The task of image captioning can be divided into two modules logically – one is an image based model – which extracts the features and nuances out of our image, and the other is a language based model – which translates the features and objects given by our image based model to a natural sentence.
For our image based model (viz encoder) – we usually rely on a Convolutional Neural Network model. And for our language based model (viz decoder) – we rely on a Recurrent Neural Network. The image below summarizes the approach given above.
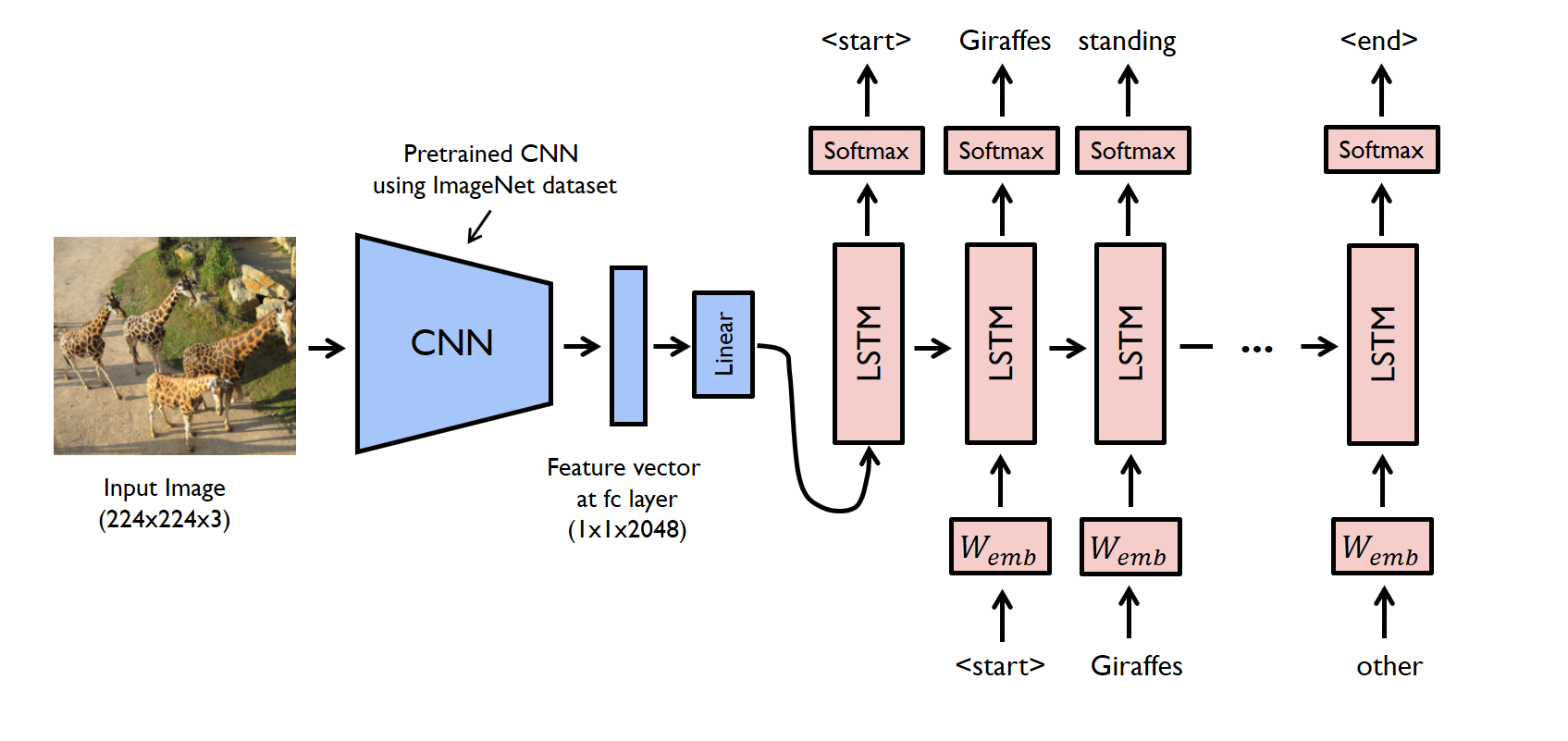
Here I'm using a pre-trained VGG16 model with weights as my CNN which will act as an input to my RNN(LSTM)
The Dataset which I used for this project is Flickr8k, Flickr30k or MS-COCO which is widey used dataset for image captioning and can also be applied in this case. I'm limited by resources to train my model on huge datasets so I chose Flickr8k. The dataset consist of 8092 images of which 4098 images are used to train the model and rest to test and validate. The prediction is not very accurate but good considering the size of the dataset. Flickr30k or MS-COCO can be used to more accurate captions.
I'm validating the caption predicted by my trained model using Bilingual evaluation understudy (BLEU) BLEU is a well-acknowledged metric to measure the similarly of one hypothesis sentence to multiple reference sentences. Given a single hypothesis sentence and multiple reference sentences, it returns value between 0 and 1. The metric close to 1 means that the two are very similar. BLEU score calculation is implemented in nltk.util and the source code is available. I found this source code is the easiest way to understand this metric. So I will go over the script to understand how the calculation works.
After BLEU is applied to the dataset we can categorize Good and Bad caption based on the score.

