The official implementation for ICLR23 paper "DIFFormer: Scalable (Graph) Transformers Induced by Energy Constrained Diffusion".
Related material: [Paper], [Blog Chinese | English], [Video]
DIFFormer is a general-purpose encoder that can be used to compute instance representations with their latent/observed interactions accommodated.
This work is built upon NodeFormer (NeurIPS22) which is a scalable Transformer for large graphs with linear complexity.
[2023.03.01] We release the early version of our codes for node classification.
[2023.03.09] We release codes for image/text classification and spatial-temporal prediction.
[2023.07.03] I gave a talk on LOG seminar about scalable graph Transformers. See the online video here.
DIFFormer is motivated by an energy-constrained diffusion process which encodes a batch of instances to their structured representations. At each step, the model will first estimate pair-wise influence (i.e., attention) among arbitrary instance pairs (regardless of whether they connected by an input graph) and then update instance embeddings by feature propagation. The feed-forward process can be treated as a diffusion process that minimizes the global energy.

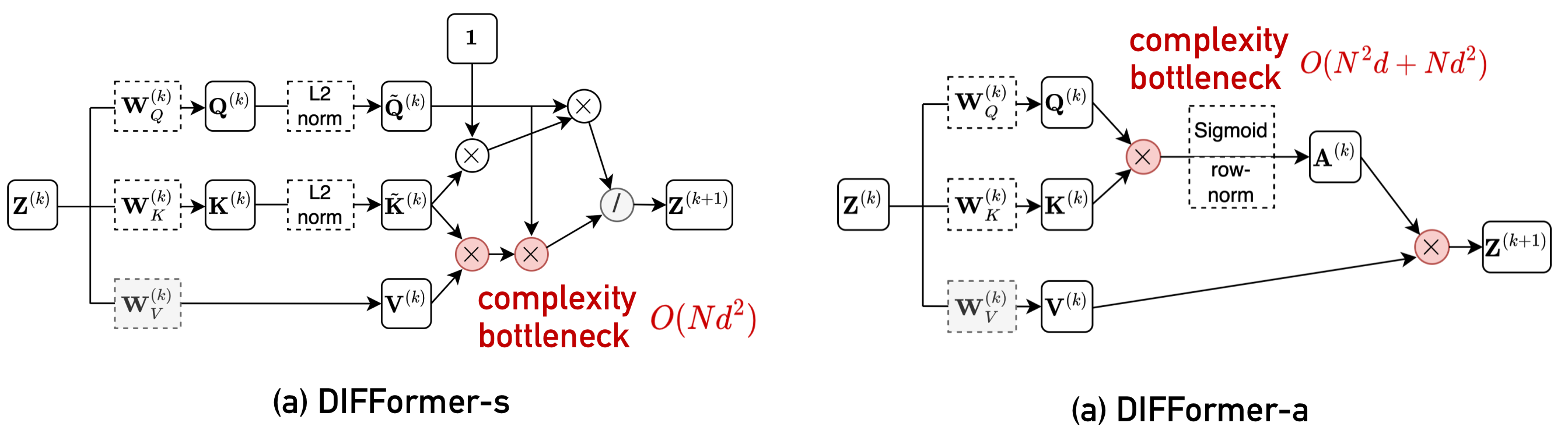
In specific, the DIFFormer's architecture is depicted by the following figure where one DIFFormer layer comprises of global attention, GCN convolution and residual link. The global attention is our key design including two instantiations: DIFFormer-s and DIFFormer-a.
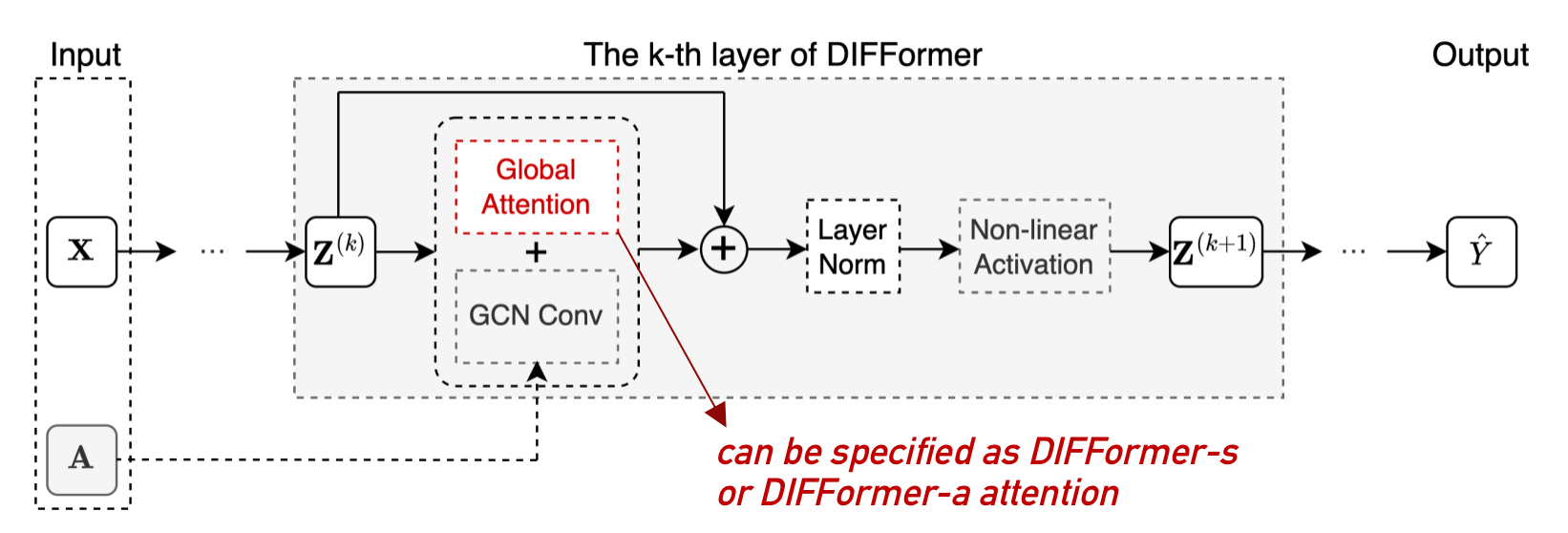
We implement the model in difformer.py where the DIFFormer-s (resp. DIFFormer-a) corresponds to kernel = 'simple' (resp. 'sigmoid'). The differences of two model versions lie in the global attention computation where DIFFormer-s only requires
We focus on three different types of tasks in our experiments: graph-based node classification, image and text classification, and spatial-temporal prediction. Beyond these scenarios, DIFFormer can be used as a general-purpose encoder for various applications including but not limited to:
- Encoding node features and graph structures: given node features
$X$ and graph adjacency$A$ , output node embeddings$Z$ or predictions$\hat Y$
model = DIFFormer(in_channels, hidden_channels, out_channels, use_graph=True)
z = model(x, edge_index) # x: [num_nodes, in_channels], edge_index: [2, E], z: [num_nodes, out_channels]- Encoding instances (w/o graph structures): given instance features
$X$ that are independent samples, output instance embeddings$Z$ or predictions$\hat Y$
model = DIFFormer(in_channels, hidden_channels, out_channels, use_graph=False)
z = model(x, edge_index=None) # x: [num_inst, in_channels], z: [num_inst, out_channels]- As plug-in encoder backbone for computing representations in latent space under a large framework for various downstream tasks (generation, prediction, decision, etc.).
Our implementation is based on Pytorch and Pytorch Geometric.
Please refer to requirements.txt in each folder for preparing the required packages.
We apply our model to three different tasks and consider different datasets.
- For node classification and image/text classification, we provide an easy access to the used datasets in the Google drive except two large graph datasets, OGBN-Proteins and Pokec, which can be automatically downloaded running the training/evaluation codes.
(for two image datasets CIFAR and STL, we use a self-supervised pretrained model (ResNet-18) to obtain the embeddings of images as input features)
- For spatial-temporal prediction, the datasets can be automatically downloaded from Pytorch Geometric Temporal.
Following here for how to get the datasets ready for running our codes.
-
Install the required package according to
requirements.txtin each folder (notice that the required packages are different in each task) -
Create a folder
../dataand download the datasets from here (For OGBN-Proteins, Pokec and three spatial-temporal datasets, the datasets will be automatically downloaded) -
To train the model from scratch and evaluate on specific datasets, one can refer to the scripts
run.shin each folder. -
To directly reproduce the results on two large datasets (the training can be time-consuming), we also provide the checkpoints of DIFFormer on OGBN-Proteins and Pokec. One can download the trained models into
../model/and run the scripts innode classification/run_test_large_graph.shfor reproducing the results.
- For Pokec, to ensure obtaining the result as ours, one need to download the fixed splits from here to
../data/pokec/split_0.5_0.25.
If you find our codes useful, please consider citing our work
@inproceedings{
wu2023difformer,
title={{DIFFormer: Scalable (Graph) Transformers Induced by Energy Constrained Diffusion},
author={Qitian Wu and Chenxiao Yang and Wentao Zhao and Yixuan He and David Wipf and Junchi Yan},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}