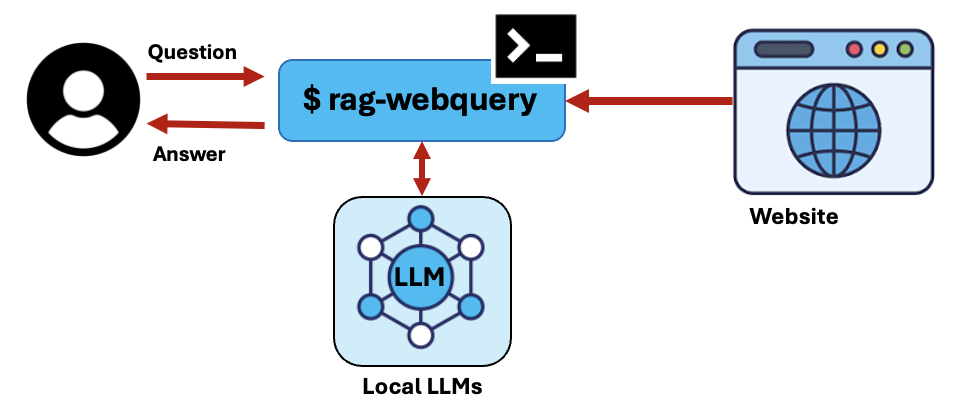
rag_webquery is a command-line tool that allows you to use a local Large Language Model (LLM) to answer questions from website contents. The utility extracts all textual information from the desired URL, chunks it up, converts it to embeddings stored in an in-memory vector store, that's then used to find the most relevant information to use as context to answer the supplied question.
- Python: The utility is written in python so you'll need Python 3.9 or greater installed.
- Ollama: To host the local LLMs you'll need to have Ollama running.
- LLM(s): The LLM(s) that you want to answer your questions need to be downloaded (pulled) with Ollama.
- GPU: A GPU is recommended but it will work with a CPU only system without one albeit slowly
- RAM: Enough system RAM to run the selected model; the default model (Zephyr 7B) requires a minium of 8GB; 16GB system recommended.
- OS: Ollama currently only runs on MacOS and Linux, Windows support coming soon.
By default rag-webquery uses the Zephyr model which is a fined tuned version of Mistral 7B. After Ollama is installed and running you need to download it with the following command:
ollama pull zephyr:latestOllama supports several other models that you can choose from in the library. If you want to use a model other than Zephyr, you'll need to pull it with Ollama and specify it with the rag-webquery '--model' flag.
The rag_webquery has be packaged and published to PyPI, so assuming you already have Python installed on your system, you can easily install it with pip with this command:
pip install -U rag_webqueryUsage documentation provided by the '--help' flag:
usage: rag-webquery [-h] [--model MODEL] [--base_url BASE_URL] [--chunk_size CHUNK_SIZE] [--chunk_overlap CHUNK_OVERLAP]
[--top_matches TOP_MATCHES] [--system SYSTEM] [--temp TEMP]
website question
Query a webpage with a local LLM
positional arguments:
website The website URL to retrieve data from
question The question to ask about the website's content
options:
-h, --help show this help message and exit
--model MODEL The model to use (default: zephyr:latest)
--base_url BASE_URL The base URL for the Ollama (default: http://localhost:11434)
--chunk_size CHUNK_SIZE
The document token chunk size (default: 200)
--chunk_overlap CHUNK_OVERLAP
The amount of chunk overlap (default: 50)
--top_matches TOP_MATCHES
The number the of top matching document chunks to retrieve (default: 4)
--system SYSTEM The system message provided to the LLM
--temp TEMP The model temperature setting (default: 0.0)
rag-webquery https://en.wikipedia.org/wiki/Ukraine "What was holomodor? What was its root cause?"Output:
### Answer:
The Holodomor was a major famine that took place in Soviet Ukraine during
1932 and 1933. It led to the death by starvation of millions of Ukrainians,
particularly peasants. The root cause of the Holodomor was the forced
collectivization of crops and their confiscation by Soviet authorities. This
policy aimed to centralize agricultural production but instead resulted in
widespread food shortages and devastating consequences for the local
population. Some countries have recognized this event as an act of genocide
perpetrated by Joseph Stalin and other Soviet notables.
In this example I'll be using the powerful "Mixtral 8x7B" model. First, I'll need to pull it via Ollama (if not already done previously):
ollama pull mixtral:latest Then I'll specify a custom system message that instructs the LLM to perform in the role of a data extraction expert that only responds with JSON formatted output. Then I ask it about Ukraine's demographics, which it will extract from the website contents and provide a JSON representation of.
rag-webquery https://en.wikipedia.org/wiki/Ukraine \
"What are Ukraine's demographics?" \
--model mixtral \
--system "You are a data extraction expert. \
You take information and return a valid JSON document \
that captures the information " \
--chunk_size 1500Output:
{
"Population": {
"Estimated before 2022 Russian invasion": 41000000,
"Decrease from 1993 to 2014": -6.6,
"Percentage decrease": 12.8,
"Urban population": 67,
"Population density": 69.5,
"Overall life expectancy at birth": 73,
"Life expectancy at birth for males": 68,
"Life expectancy at birth for females": 77.8
},
"Ethnic composition (2001 Census)": {
"Ukrainians": 77.8,
"Russians": 17.3,
"Romanians and Moldovans": 0.8,
"Belarusians": 0.6,
"Crimean Tatars": 0.5,
"Bulgarians": 0.4,
"Hungarians": 0.3,
"Poles": 0.3,
"Other": 2
},
"Minority populations": {
"Belarusians": 0.6,
"Moldovans": 0.5,
"Crimean Tatars": 0.5,
"Bulgarians": 0.4,
"Hungarians": 0.3,
"Romanians": 0.3,
"Poles": 0.3,
"Jews": 0.3,
"Armenians": 0.2,
"Greeks": 0.2,
"Tatars": 0.2,
"Koreans": {
"Estimate": "10-40000",
"Location": "mostly in the south of the country"
},
"Roma": {
"Estimate (official)": 47600,
"Estimate (Council of Europe)": 260000
}
},
"Internally displaced and refugees": {
"Due to war in Donbas (late 2010s)": 1400000,
"Due to Russian invasion (early 2022)": 4100000
}
}Pretty good, the output is valid JSON, but to get the response in a specific, consistent structure you can provide an empty JSON template of the desired structure/fields as part of your prompt (question).